MongoDB vs. RavenDB
Keď robia dvaja to isté, tak to môže byť vo výsledku úplne iné.
V tomto článku popisujem to, ako som sa dostal k MongoDB a RavenDB, moje skúsenosti s týmito dokumentovými databázami na malom reálnom projekte s reálnymi dátami. Tiež sa snažím zhrnúť rozdiely v prístupoch pri implementácii a problémy, ktoré som musel riešiť.
RavenDB popisujem viac, pretože je o dosť menej známa ako MongoDB. Treba povedať, že porovnanie nie je vyčerpávajúce a plno oblastiam som sa nevenoval. Taktiež predpokladám, že v ďalších verziách sa veci môžu zmeniť.
Zoznámenie sa s NoSQL
Od strednej školy som sa venoval PHP a MySQL. Neskôr som na vysokej škole v týchto technológiách pokračoval a aj pracoval (v práci som začal narážať na limity MySQL). Následne som sa na inžinierskom štúdiu v rámci tímového projektu dostal ku MS SQL a pri práci som zistil, aké bolo MySQL neschopené a hlavne pomalé.
O rok na to (2013) v mojom okolí začal byť hype okolo NoSQL databáz a začali sa používať aj tam, kde by sa nemali. Prednášky o prechode na MongoDB sa vždy niesli v duchu: "použili sme najpomalšiu databázu aká jestvuje (MySQL), s najpomalším frameworkom v Pythone alebo Ruby on Rails a je to (prekvapivo) pomalé." A potom sme prešli na MongoDB a je to rýchlejšie. Lenže bolo by to rýchlejšie, keby použijú čokoľvek iné.
Medzičasom sa z MongoDB stal symbol NoSQL sveta.
Poznámka: Pri materiáloch o MySQL sa dočítate, že treba byť s JOIN-ami opatrní, lebo sú veľmi pomalé. Pri materiáloch o MS SQL sa dočítate, že sa nemáte báť JOIN-u, lebo je to najrýchlejšia relačná operácia.
Neskôr som si robil nejaké súkromné projekty na MongoDB, lebo ma táto databáza niečím fascinovala (možno začiatočníckou jednoduchosťou alebo BigData pátosom). No zisťoval som, že na rovnakom HW je pomalšia ako MS SQL, a to aj pri bežných dopytoch tak aj pri gespatial operáciách. (Asi najextrémnejší rozdiel som pocítil na databáze importovanej z Geonames, kde som počítal konvexnú obálku bodov pre Slovenské mestá – pomocou map-reduce v Mongu som sa údajom dostal za 4 minúty, keď som na to isté použil MS SQL 2016 tak to trvalo 230 ms.)
Začiatky s RavenDB
O RavenDB som sa dozvedel dávnejšie (2016), ale odradili ma mýty, ktoré okolo tejto databázy panovali (že je pomalá, žerie veľa RAM, že všetky dokumenty sú v jednej kolekcii,…).
Neskôr sa mi dostala do povedomia cez prednášky o performace .Net Frameworku a problémoch, ktoré museli prekonať, aby dosiahli požadovanú rýchlosť.
A keď som sa k RavenDB konečne dostal a čítal si o nej, tak som nechápal, prečo by to niekto používal, veď MongoDB má tie isté featury…
No to bol len prvý pohľad, keď som sa ponoril hlbšie a hlavne si vyskúšal indexy, tak som to pochopil v čom sú hlavné výhody RavenDB. A vyskúšal som si ju na niekoľkých projektov.
V ďalšom texte zhrňujem niektoré zaujímavé featurey tejto databázy a porovnávam ju s MongoDB na jednom konkrétnom projekte - Area52.
Čo je to RavenDB
RavenDB je open-source, dokumentová, distribuovaná, NoSQL databáza, ktorá je od svojho vzniku (2010) podporuje transakcie a je na stavaná. Taktiež podporuje master-to-master replikáciu. Je vyvíjaná spoločnosťou Hibernating Rhinos Ltd.
To asi nepovedalo veľa, tak skúsim opísať jej principiálne fungovanie (implementačné detaily sa môžu líšiť).
RavenDB má v jadre key-value databázu nazývanú Voron, kde kľuč je ID dokumentu a hodnota je JSON dokument. Táto databáza je full ACID a MVCC. Taktiež je vďaka časovým značkám ku hodnotám veľmi ľahko distribuovateľná a replikovateľná aj pri výpadkoch spojenia.
Nad touto internou databázou je postavený indexovací engin pomocou upraveného Lucene.Net (od verzie 5.4 by mal byť dostupný aj nový engin Corax). Index v ponímaní RavenDB by sa dal predstaviť vo svete relačných databáz ako materializovaný pohľad, nad ktorým sú ďalšie indexy. Takže v indexe ide robiť filtrovanie, transformácie, výpočty (jeden dokument môže mať v indexe 0 až N položiek). A to nie je všetko, keďže RavenDB sa tvári ako keby všetky dokumenty sú v jednej kolekcii, tak je do jedného indexu možné vytiahnuť dokumenty s viacerých kolekcií, v rámci indexu robiť niečo ako JOIN. Je možné použiť map-reduce indexy. A keďže sa ako indexovací engin používa Lucene.Net, tak RavenDB má k dispozícii funkcionlitu podobnú ako ElasticSerach.
No tu treba upozorniť na to, že všetky operácie nad dokumentmi (insert, update, delete, modifikácia a vyhľadanie podľa ID,…) majú garantované ACID správanie, no indexy sú len eventuálne konzistentné, respektíve môžeme to považovať za implementáciu CQRS (ale cez API je možné zistiť stav indexu a výsledkov).
Nad tým všetkým je ešte query procesor, processing engine a RavenDB Studio.
RavenDB ďalej poskytuje podporu časových sérií, distributed counters, geospatial index, subscriptions, súborové prílohy dokumentov, revízie dokumentov, hromadné patche, atomické operácie, substcribtions, notifications, možnosť použiť embedded verziu, priamo databáza obsahuje administračné GUI, v ktorom je naozaj všetko,… a mnohé mnohé ďalšie funkcionality a integrácie (na Kafku, RabbitMQ, Graphanu, SQL databázy,…).
MongoDB vs. RavenDB na reálnom projekte
MongoDB a RavenDB som si chcel vyskúšať na niečom reálnom (a hlavne vhodnom pre dokumentovú databázu). Tak som si spravil projekt, ktorý umožňuje ukladať a vyhľadávať v štruktúrovaných logoch (sú to nerelačné dáta a dá sa ich zohnať alebo vytvoriť dostatočné množstvo).
Navyše existujúce riešenia ako ELK stack, Loki, či Seq mi v niečom nevyhovovali.
Tak vznikol projekt Area52.
Area52 umožňuje vyhľadávať v štruktúrovaných logoch pomocou vlastného dopytovacieho jazyka, ktorý sa prekladá do dopytovacieho jazyku príslušnej databázy.
Časové rady, ktoré podporujú obe databázy, šlo použiť pri vykresľovaní grafov rôznych udalostí alebo metrík z logov (napríklad počet chýb za deň, priemerného času odpovede servera, tržby,…).
V nasledujúcich podkapitolách ukážem rozdiely pri práci s týmito dvoma databázami (údaje o nich sa vzťahujú na dobu vydania tohto článku).
Ukladanie dokumentov
Prvý najviac očividný rozdiel je to, že v MongoDB musí mať každý dokument svoje ID priamo v sebe. V RavenDB dokument nemusí obsahovať svoje ID (interne ho neobsahuje ani keď je v modeli).
Klient RavenDB používa Unit of Work pattern a preto ide napríklad zistiť ID dokumentu ešte pred tým, ako sa uloží (keď chceme ukladať súvisiace dokumenty v transakcii).
Tu celkovo MongoDB ťahá za kratší koniec, lebo som musel denormalizovať denormalizovaný dokument, a pridať doň filedy, ktoré potrebovali indexy alebo vyhľadávanie a tiež field pre fulltext a samozrejme pridať do dokumentu filed s jeho verziou. Celkovo v MongoDB treba občas ukladať tie isté dáta na viackrát do rôznych kolekcií.
Zatiaľ, čo RavenDB tento neduh eliminuje indexmi a možnosťou hromadného patchu dokumentov.
MongoDB má umelý limit na veľkosť dokumentu 16MB, tento limit platí aj na všetky operácie s ním (aj na vstup a výstup), RavenDB nemá maximálny limit pre dokumenty ale technicky sú to 2GB (no neodporúča používať tak veľké JSON-y).
Príklad v projekte: V projekte Area52 do RavenDB ukladám priamo doménový objekt pre štruktúrovaný log. Zatiaľ, čo v prípade MongoDB som musel implementovať databázové modely, lebo potrebovali dodatočné filedy (field pre fulltext vyhľadávanie, fieldy pre hodnoty pre case insesnitive vyhľadávanie,…), verziu a ID. Podobné to bolo pri ostatných doménových objektoch.
Čo sa týka zabraného miesta na disku, tak obe databázy boli vo výsledku na tom rádovo rovnako.
Transakcie
Ako som už spomínal RavenDB je od začiatku navrhnutá s podporou transakcií, v API sa používajú implicitne a fungujú vždy a všade.
MongoDB už multi-dokumentové transakcie už má, no cesta k nim bola tŕnistá. Nejakú podporu transakcií má Mongo od verzie 3.4, no nie vždy fungovali v rámci clastru a dlho mali obmedzenie na 16MB dát (do verzie 4.2). Takisto sa v čase menilo správanie transakcií a aj v kombinácii s nastavením serveru (podľa toho, čo som čítal bolo potrebné mať na serveri nastavené potvrdzovanie zápisov aby fungovali spoľahlivo, niektoré transakčné API neboli dostupné v komunitnej verzii, transakcie sa správali inak ak sa prevádzkoval jeden nod a inak ak ich bolo viac).
MongoDB používa pre transakcie explicitné API, oficálna dokumentácia používateľov odrádzajú od ich použitia, defaultné nastavenia serveru negarantujú durability a na svojich stránkach varujú, že použitie transakcií má veľmi negatívny dopad na výkon - https://www.mongodb.com/docs/manual/core/transactions/.
Príklad v projekte: V projekte Area52 používam implicitné transakcie pre RavenDB. No pre MongoDB nie a to hlavne kvôli výkonu a tomu, že klientska strana nevie zaručiť durability.
Indexy
MongoDB používa to, čo si ako prvé predstavíme pod klasickými indexmi. Podporuje indexy pre jeden filed, zložené indexy, gesopatial indexy, TTL indexy (len prečo je na to potrebné vytvárať samostatný index?), je možné indexovať aj polia a v novších verziách aj filtrované indexy. No nie vždy plánovač tieto indexy aj využije. A je tu obmedzenie na to, že kolekcia môže mať len jeden fulltext index. Celkovo sú to štandardné indexy.
V RavenDB sú indexy úplne iná káva. Je to takmer „strieborná guľka“ a takmer akýkoľvek problém ide v tejto databáze vyriešiť indexom.
Indexy sa definujú deklaratívnym kódom, umožňujú:
- kombinovanie polí v indexoch,
- vykonávanie výpočtov v indexoch,
- agregáciu dokumentov pred indexovaním (dá sa to predstaviť ako náhrada JOIN-u),
- filtrovanie dokumentov alebo naopak indexovanie viacerých hodnôt s dokumentu,
- podpora indexovanie hierarchických hodnôt,
- podpora indexovania countrov, časových sérií a príloh v rámci dokumentu,
- pre výpočty a spracovanie dát v indexoch použiť vlastný kód a knižnice (C# a JavaScript),
- ukladať hodnoty do indexov,
- dynamické indexy (dynamické vytváranie položiek v indexe),
- geospatial indexy,
- indexovanie dokumentov z viacerých kolekcií do jedného indexu,
- samostatný fulltext s rôznym nastavením pre jednotlivé fieldy,
- map-reduce indexy…
Samozrejme tieto všetky vlastnosti idú kombinovať. Indexy sa dopočítavajú asynchrónne (na štýl CQRS), takže nespomaľujú operácie s dokumentmi, to má ale aj nevýhodu v tom, že nie je možné vytvoriť uniq constraint (čo naopak MongoDB umožňuje). Možnosti indexovania sú v RavenDB naozaj ohromné a ako som spomínal indexy tu skôr pripomínajú materializované pohľady.
Pár príkladov:
- Pekný príklad je „CASCADE DELETE“ – Mongo niečo také nepodporuje a človek si musí dané dokumenty načítať, vytiahnuť interpretovať a vytiahnuť si súvisiace dokumenty a následne to zmazať. V RavenDB je na to možné použiť multimap index a mazať priamo podľa neho.
- Univerzálne fulltext vyhľadávanie - vďaka multimap indexom je možné vytvoriť vyhľadávanie cez viaceré kolekcie (napr: používatelia, články a komentáre).
- Map-reduce indexy - nahradzujú klasický map-reduce a agregácie, len s tým, že výsledky sú predpočítané a indexované dopredu, takže vyhľadávanie v nich je rýchle a o aktuálnosť sa stará databáza.
Možnosti indexov v RavenDB majú vplyv aj na to ako vyzerá databázová schéma. V štandardnej dokumentovej databáze je potrebné ukladať dáta na viackrát do rôznych kolekcií, lebo v aplikácii sú na ne potrebné rôzne pohľady alebo je to potrebné hľadiska výkonu - https://www.youtube.com/watch?v=2cZpC94P2Pw (pri tom by sa hodili transakcie, však). Toto RavenDB svojimi indexami do značnej miery eliminuje. Tiež to uľahčuje situáciu, keď je treba zmeniť aplikáciu, proste sa len pridá alebo zmení index a dokumenty sa nemusia verzovať alebo updatovať. Takže komplexitu schémy a aplikačnej logiky sa dá preniesť na plecia deklaratívnych indexov.
Poznámka: To, že je bezschémová databáza agilnejšia, respektíve dokumentová databáza je agilnejšia ako relačná považujem za veľmi rozšírený mýtus. Pretože jednak schéma databázy je v aplikácii a s dátami neznámej schémy sa nedá dobre pracovať. Druhá vec je, že pri návrhu schémy treba vedieť dopredu, aké dopyty budú použité (a to tvrdia priamo ľudia z Monga – https://www.youtube.com/watch?v=2cZpC94P2Pw). Zatiaľ čo pri relačnom modely sa prosto začne s normalizovaným modelom a následne je možné sa dopytovať na akékoľvek dáta.
Príklad v projekte: Pre kolekciu logov mám v projekte 6 samostatných indexov pre MongoDB, navyše sa preň musia v aplikácii dopočítavať dodatočné filedy pre vyhľadávanie. V RavenDB je to riešené jediným indexom.
Nasleduje ukážka multimap-reduce indexu, ktorý rieši detail pre korpus-dokument v inom projekte, ktorý sa zaoberá kontrolou plagiátorstva:
public class CorpusWithDocCountIndex : AbstractMultiMapIndexCreationTask<CorpusWithDocCountIndex.Result> { public class Result { public string Id { get; set; } public string? Name { get; set; } public string? UserId { get; set; } public CorpusType? Type { get; set; } public int DocumentCount { get; set; } } public CorpusWithDocCountIndex() { this.AddMap<Corpus>(corpuses => from c in corpuses select new Result() { Id = c.Id, UserId = c.Owner.UserId, DocumentCount = 0, Name = c.Name, Type = c.Type }); this.AddMap<Document>(documents => from q in documents select new Result() { Id = q.Corpus.Id, UserId = null, DocumentCount = 1, Name = null, Type = null }); this.Reduce = t => t.GroupBy(q => q.Id) .Select(k => new Result() { Id = k.Key, DocumentCount = k.Sum(q => q.DocumentCount), Name = k.Select(q => q.Name).FirstOrDefault(q => q != null), Type = k.Select(q => q.Type).FirstOrDefault(q => q != null), UserId = k.Select(q => q.UserId).FirstOrDefault(q => q != null) }); this.Index(t => t.UserId, FieldIndexing.Exact); } }
Dopytovanie
Asi najvýraznejší rozdiel medzi MongoDB a RavenDB je v dopytovanom jazyku.
MongoDB má tri spôsoby ako sa dopytovať do databázy:
- vyhľadanie a projekcia dokumentov z kolekcie (find + projection),
- agregačný framewrok (postup krokov skladajúcich sa z krokov s filtrovaním, projekciou a grupovanim)
- map-reduce (ako javascript funkcie, no dnes je už preferovaný agregačný framework).
Budem sa tu venovať prvým dvom spôsobom získavania dát. Prvý je jednoduché filtrovanie s voliteľnou projekciou. Druhý je agregačný framewrok, v ktorom je možné veľmi flexibilne kombinovať kroky, čo má svoje výkonové dopady, ale zas veľkú vyjadrovaciu silu.
V oboch prípadoch sa na definíciu dopytovania, grupovania a projekcií používajú BSON dokumenty. Čo nie je príliš pekné ani krátke, lebo ide o kombináciu stringov, BSON dokumentov a polí, ktoré sa zanorujú do seba. V javascripte je tento zápis relatívne stručný. Napríklad:
db.inventory.find({ $or: [{ status: "A" }, { qty: { $lt: 30 }}]})
No v typových jazykoch nepríjemne rastie a stáva sa neprehľadný so zvyšujúcou sa komplexitou a je ľahké sa stratiť v záplave zátvoriek a stringových operátorov.
Tiež tu máme to nepríjemné obmedzenie veľkosti spracovaných dokumentov na výstupe a v medzi-krokoch.
RavenDB používa jazyk RQL, ktorý sa najviac podobá LINQ-u (a ten sa podobá SQL-ku), umožňuje jednoducho vyjadriť filtrovanie a projekcie. Pre mňa je tento jazyk oveľa jednoduchší a intuitívnejší, ako skladanie vnorených BSON dokumentov. Navyše RavenDB klient má silnú podporu LINQ-u v C#, takže človek sa jednoducho dopytuje v typovom jazyku (ostatné drivre pre iné jazyky majú k tomu svoju alternatívu).
Predchádzajúci príklad by mal v RQL takúto alternatívu (s indexom pre status a qty):
from index 'Inventory/Base'
where status = 'A' or qty < 30
Pri dopytovaní treba poznamenať, že v RavenDB sa dopytuje a triedi vždy cez index (takže sa Ad-hoc dopytmi to nie je také jednoduché). Ak sa v C# klientovi (v defaultnom nastavení) pokúsite dopytovať priamo na fieldy dokumentov, tak dostanete výnimku s tým, že sa máte dopytovať na index. RavenDB ale dokáže pri prvom dopyte vytvoriť potrebný index a použiť ho, ale nie je to odporúčané (hlavne nie v produkcii). Navyše tým, že sa explicitne uvedie index, máte istotu, že sa použije.
Trošku komplikovanejšie je to agregáciami, tie v RavenDB ide použiť len cez map-reduce index, alebo cez facet-y.
Viac o rozdieloch v dopytovaní (MongoDb vs. RavenDB so zameraním na agregácie) je možné nájsť tu https://www.youtube.com/watch?v=1g-6XocHG6U.
Príklad v projekte: Na nasledujúcom obrázku je príklad dopytu v MogoDb (naľavo) a RavenDB (napravo) pre zistenie podielu aplikácií v logoch. Dopyty sú na tie isté štruktúry a obe majú indexy.
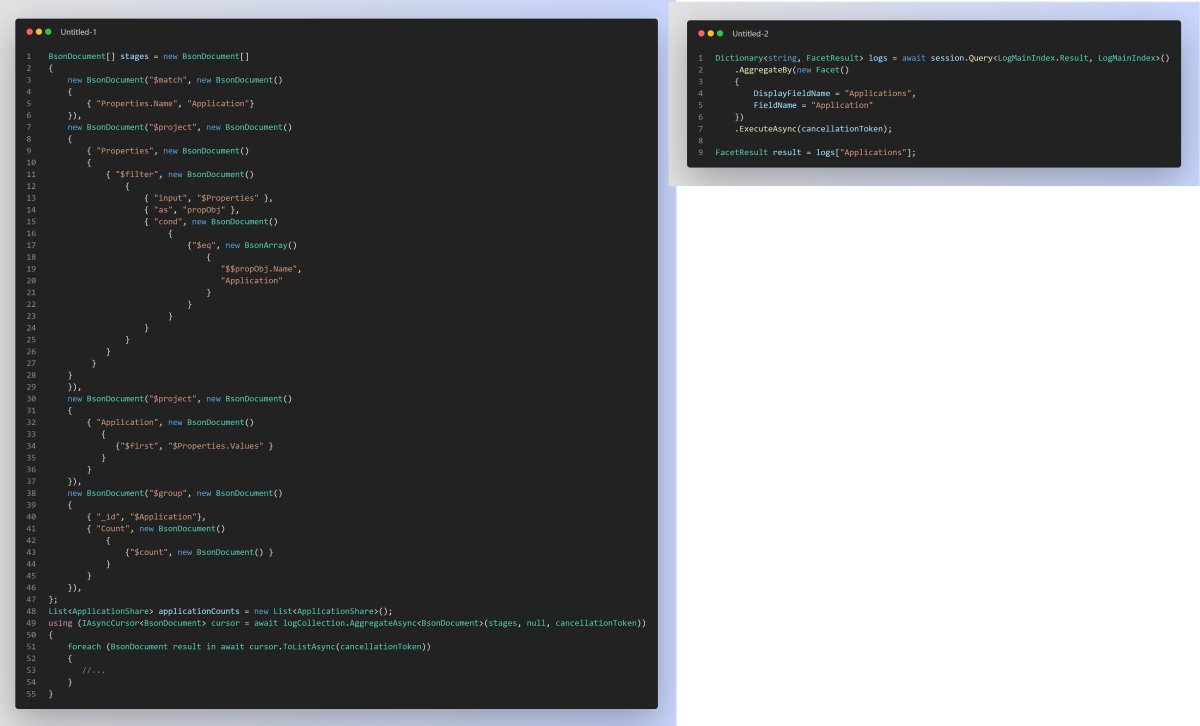
Celkovo všetky dopyty pre MobgoDb boli 4 až 8-krát dlhšie ako v prípade RavenDB. Taktiež mi pre MongoDB chýbali operácie na prácu so stringami (napr. startsWith).
Časové rady - TimeSeries
Časové rady v MongoDB sú implementované ako špeciálna kolekcia, ktorá používa ako ID čas udalosti. Dopytuje sa naň cez agregačný framework.
RavenDB má časové rady naviazané na dokument, v ktorom ich môže byť viac a sú pomenované. Na dopytovanie používa RQL ale pre operácie nad časovými radmi má vlastnú sadu agregačných funkcií a veľmi dobré možnosti ako učiť časové okno pre agregáciu, navyše je možné kombinovať rôzne časové rady.
Príklad v projekte: Tu je rovnaká situácia ako pri dopytovaní – dopyt pre časové rady je RavenDB výrazne kratší. V MongoDB som vytvoril len jednu kolekciu pre časové rady a rôzne hodnoty pre časové rady oddeľujem tagom, to asi nie je najlepšie riešenie, ale dynamicky vytvárať nové kolekcie sa tiež neodporúča. V RavenDB som mohol vytvárať samostatnú časovú radu pre každú používateľskú definíciu. Taktiež časové okno šlo určiť presne, zatiaľ čo v Mongu to bol vždy len derivát časového údaju (rozumej granularita len na hodinu, minútu, sekundu, deň, mesiac,…).
Subscriptions
V tejto podkapitole je porovnaný mechanizmus umožňujúci sledovať zmeny v kolekcii z klientskej aplikácie a reagovať na ne. Ide pomocou neho implementovať napríklad background processing.
V MongoDB nazývané Changed streams slúžia pre informovanie aplikácií o zmenách dokumentov v kolekcii. No majú viac formu notifikácií. Je v nich možné použiť token pre pokračovanie v sledovaní pri výpadku aplikácie ale o jeho ukladanie a použitie si musí aplikácia riešiť sama.
Poznámka: Changed streams v MongoDB funguje len keď je spustený ako replica set.
V RavenDB sa toto celé rieši na strane serveru a spracovanie dokumentov aj pri subsripcii je transakčné, zabezpečuje, že rovnakú zmenu nezachytia dve aplikácie.
Príklad v projekte: Túto vlastnosť som nepoužil v Area52, ale v inom projekte, kde som ju používal pre spracovávanie novo pridaných textových dokumentov (MS Office dokumenty a PDF-ka).
Zhrnutie databáz
V tejto kapitole uvádzam krátke subjektívne zhrnutie týchto dvoch databáz a pridávam nejaké postrehy.
MongoDB
MongoDB za svoju existenciu ubehlo dlhú cestu a zlepšuje sa (od hlúpeho úložiska s map-reduce ku úložisku s agregačným frameworkom, časovými sériami atď.).
Čo sa mi páči:
- Dokumentácia.
- Veľká komunita vďaka rozšírenosti.
- Verzia zadarmo má minimálne obmedzenia (no nejaké sú) a nelimituje výkon.
- GridFS (MongoDB je vhodnejšia databáza na ukladanie binárnych dát).
Čo sa mi nepáči:
- Komplikovaný dopytovaní (ne)jazyk.
- Chýbajú elementárne operácie so stringami.
- Ku reálnym transakciám sa dá veľmi ťažko dopracovať a to aj za cenu poklesu výkonu.
- Vlastnosti a správanie featúr sa veľmi menili medzi verziami, z čoho vzniká chaos pri radách, článkoch a best practice.
- Nemožnosť master-master replikácie.
- GridFS nepodporuje transakcie.
- Veľmi slabé administračné GUI, kde nejde prakticky nič nastaviť alebo si pozrieť.
- MongoDB klame, v administračnom GUI sa dozviem, že dáta v databáze majú s indexami 16MB ale na disku majú 370MB.
- C# driver vie serilizovať štruktúry ale už ich nevie deserializovať.
RavenDB
RavenDB na mňa pôsobí veľmi solídnym dojmom, kde kombinuje zaujímavé koncepty. Vyžaduje trochu iný prístup, na aký sú programátori zvyknutý. Taktiež sa o nej menej hovorí a vie, čo je podľa mňa veľká škoda.
Čo sa mi páči:
- Reálne transakcie a ACID.
- Atomické commandy.
- Indexy, indexy, indexy.
- Lazy queries (mechanizmus umožňujúci odoslať viac dopytov na server v jednej dávke a tým znížiť celkový čas odozvy a priepustnosť).
- Podpora integračného testovania.
- Dokumentácia.
- Spracovanie textu (v podstate vie nahradiť funkcionalitu ElasticSerach).
- Rýchlosť. Napriek verzii obmedzenej na tri jadrá a 6GB RAM, bola RavenDB rýchlejšia pre niektoré dopyty a inserty ako MongoDB na ôsmich jadrách a 16GB RAM, cítiť to bolo hlavne pri agregáciách.
- Priamo súčasťou databázy je perfektné administračné GUI (obrázky nižšie), v ktorom ide nastaviť všetko, od vlastností databázy až po cluster. Je v ňom možné prezrieť stav úložiska, dokonca vliezť do indexov a pozrieť sa ako sú zaindexované hodnoty a ako vyzerá zvnútra, či si vizualizovať vnútornosti map-reduce indexu, backupy, performace hinty a mnoho mnoho ďalšieho. A toto GUI neklame, keď máte na disku 300MB databázu, tak sa to dozviete aj z GUI.
- Otvorenosť. A to nemyslím len otvorenosť zdrojových kódov. Ale to, že tvorcovia RavenDB vo svojich blogoch a prednáškach opisujú, ako fungujú vnútornosti databázy a hlavne prečo sa rozhodli veci riešiť tak ako sa rozhodli. K tejto otvorenosti prispieva aj spomínané administračné GUI.
- Jednoduchší dopytovací jazyk, priateľskejší klient pre C#.
- Mám pocit, že celé to má nejaký koncept a smer, že tvorcovia nad RavenDB a jej použitím rozmýšľajú.
Čo sa mi nepáči:
- Dosť obmedzená komunitná licencia, čo podľa mňa bráni širšiemu rozšíreniu, zišlo by sa pridať pár jadier procesora pre cluster.
- Príloha nejde čítať po častiach (otvoril som na to diskusiu).
- V defultnom nastavení majú ID-čka tvar, ktorý nie je vhodné posielať von zo systému (dá sa to zmeniť, alebo upraviť, no je to nejaká malá práca navyše).
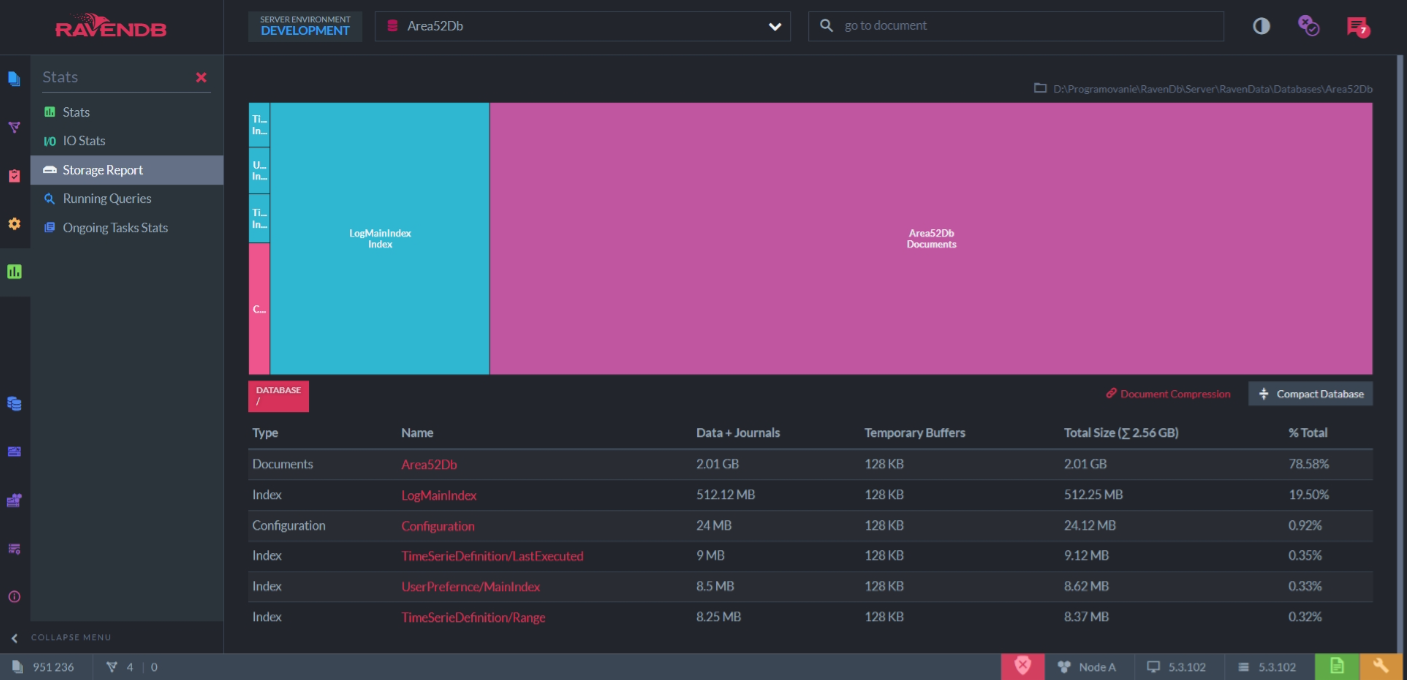
RavenDB Studio - Vizualizácia dát na disku pre databázu.
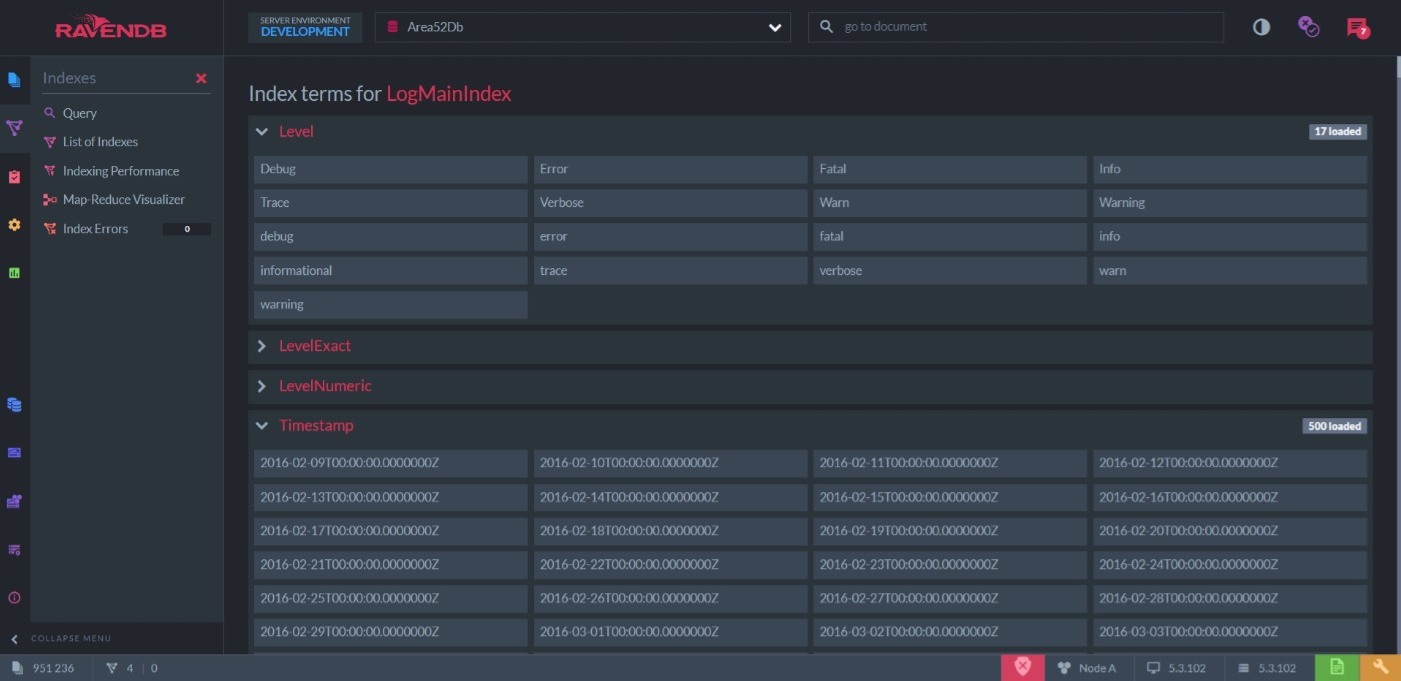 RavenDB Studio - Zobrazenie hodnôt v indexe.
RavenDB Studio - Zobrazenie hodnôt v indexe.
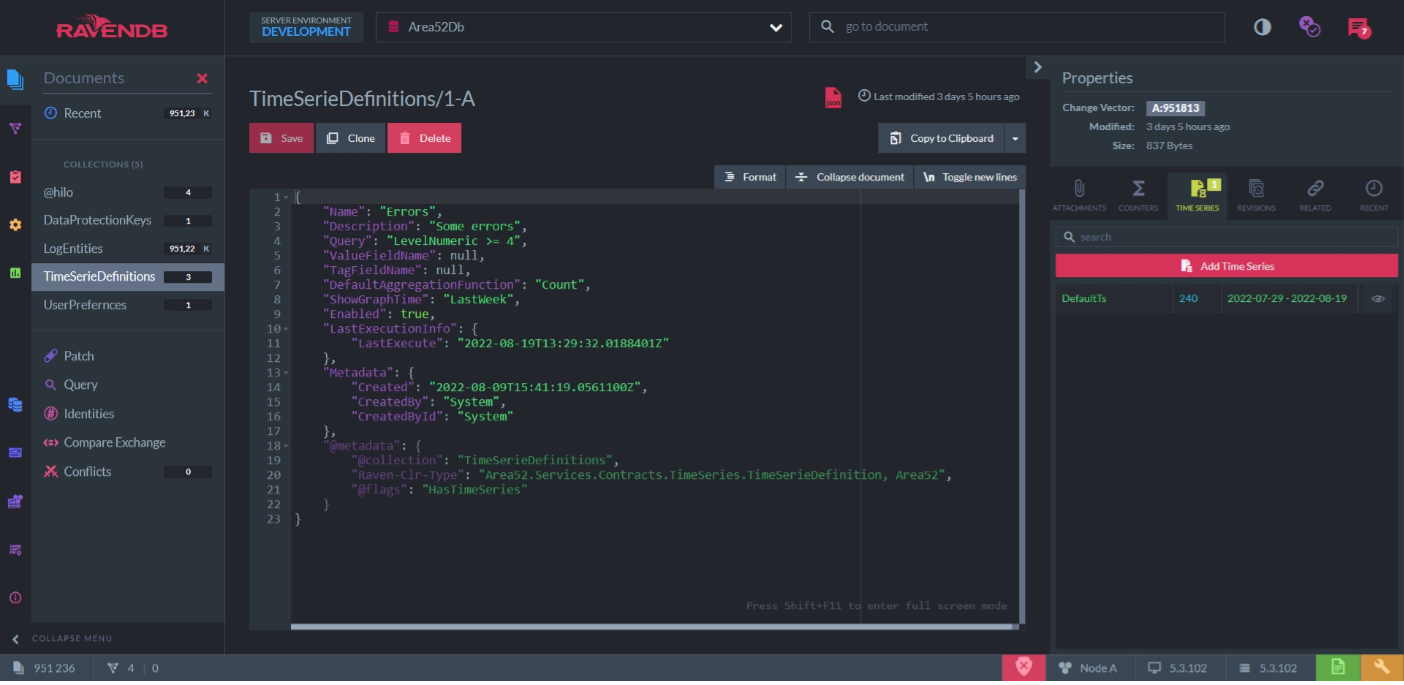 RavenDB Studio – Zobrazenie dokumentu s rozkliknutými časovými radmi.
RavenDB Studio – Zobrazenie dokumentu s rozkliknutými časovými radmi.
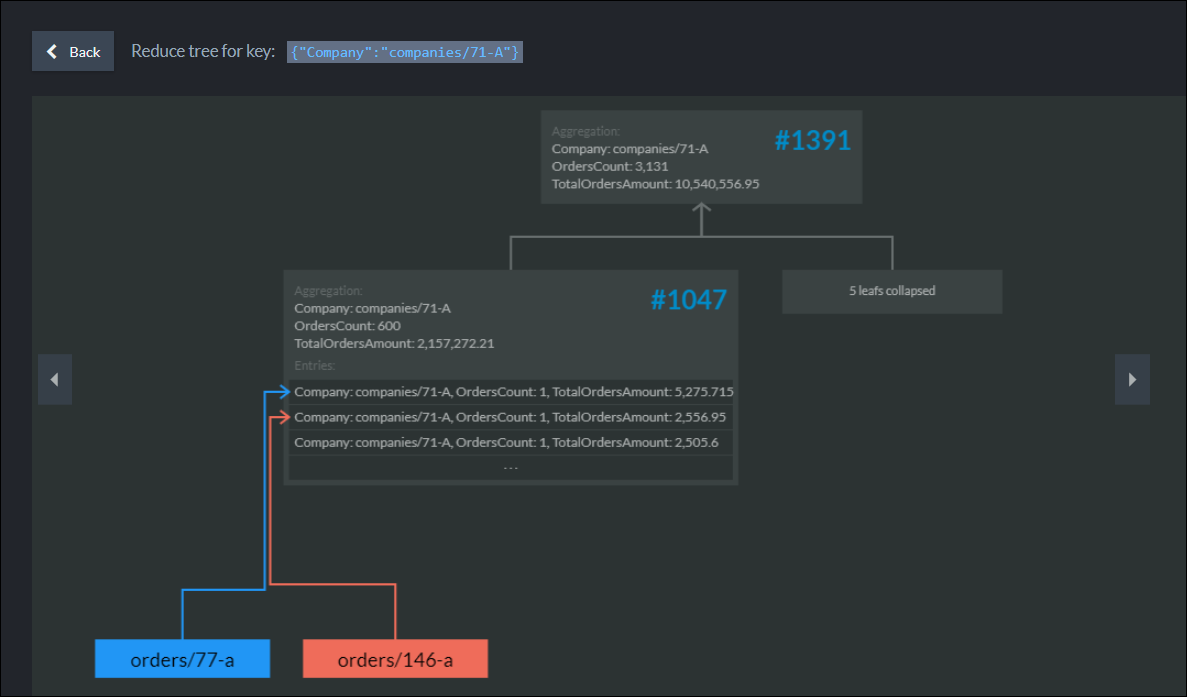 RavenDB Studio – Vizualizácia map-reduce indexu.
RavenDB Studio – Vizualizácia map-reduce indexu.
Zhodnotenie
Na začiatku som opisoval moje skúsenosti s relačnými databázami, lebo mi príde, že MongoDB je MySQL dokumentových databáz - veľmi rozšírená, obľúbená databáza, ktorá sa stala defakto štandardom a každý po nej siahne, lebo o nej počul. Síce má množstvo featúr, no pôsobia nedokončene a polovičato. Pričom RavenDB by som prirovnal k MS SQL, síce platená, ale s premyslenými featurami, ktoré fungujú. Má k dispozícii plnohodnotný administračný nástroj, v ktorom ide spravovať databázu, kontrolovať a ladiť výkon,… a to bez toho, aby sa človek musel v konzole písať komandy, alebo nastavovať konfiguračné súbory v proprietárnom formáte.
MongoDB by som uprednostnil v prípadoch, keď na ACID vlastnostiach až tak nezáleží, a v prípadoch, ak je potrebné len úložisko dát.
RavenDB by som uprednostnil tam, kde ide o peniaze a o zdravie – ACID, tam, kde je potrebné viac pracovať s dátami (hlavne z rôznych zdrojov), tam, kde ide o vyhľadávanie a spracovanie textu alebo sa hodí CQRS architektúra kvôli výkonu,…
MongoDB bola láska na prvý pohľad, je to zaujímavá databáza, ale RavenDB je zaujímavejšia.
Zdroje
- https://www.youtube.com/watch?v=P4T7MOlxsUs - KROS Dev Meetup #7 -RavenDB is a NoSQL Document Database (Marián "vlko" Vlčák)
- https://www.youtube.com/watch?v=1e6dS9jSQWo - RavenDB: a really boring database! with Dejan Miličić (ukážka RavenDB pre začiatočníkov)
- https://indexoutofrange.com/RavenDBvsMongoDB/ - RavenDB vs MongoDb
- https://www.youtube.com/watch?v=2cZpC94P2Pw - The Developer's Guide to Data Modelling with Document Databases - Adrienne Braganza Tacke
- https://www.youtube.com/watch?v=1g-6XocHG6U - MapReduce: RavenDB vs MongoDB
- https://www.youtube.com/watch?v=5ZXBR3croMA - MongoDB vs RavenDB: Which Document Database Conquers ACID?
- https://www.youtube.com/watch?v=Jd1vYmhwpAQ - Migrating from RavenDB 2.5 to 4.0 in 36,000 Locations
- https://www.youtube.com/watch?v=qeWY1RuIlaE - ExDav proj - MongoDB, CosmosDB, CalDAV, MS Graph [M. Melena, HAVIT Vzdělávací okénko, 23.2.2022]
- https://ayende.com/blog/ - Oren Eini aka Ayende Rahien (blog CEO Hibernating Rhinos)
- https://ravendb.net/docs/article-page/5.4/csharp - RavenDB dokumentácia
- https://alex-klaus.com/ravendb-pain-and-joy/ - RavenDB. Two years of pain and joy
- https://www.mongodb.com/docs/ - MongoDB dokumentácia
- https://analyticsindiamag.com/the-good-the-bad-and-the-ugly-the-story-of-mongodb/ - The good, the bad and the ugly – the story of MongoDB