Ako som robil BouncyHsm
V tomto článku popisujem, ako som robil softvérovú implementáciu HSM-ka (hardware security module), dôvody prečo som sa rozhodol pustiť do projektu, ktorý takmer nik nevyužije, návrhu architektúry, komunikačného protokolu a slepých uličiek, a nakoniec, ako sa vďaka tomu stal kontribútorom BouncyCastle.
Začalo to tak, že som chcel spraviť prototyp systému, ktorý dokáže overiť TOTP (Time-based one-time password) bezpečne, to znamená, že zdieľané tajomstvo nebude v čitateľnej podobe ani v databáze ani v RAM služby (ako obrana voči memory dumpu) Chcel som na to využiť HSM a jeho existujúci simulátor SoftHSMv2, ale ten nemal podporu potrebných mechanizmov (algoritmov). Vtedy mi došla trpezlivosť a začal som rozmýšľať ako to vyriešiť.
Výsledkom je BouncyHsm.
HSM, PKCS#11
Najskôr trochu nevyhnutnej teórie…
HSM je hardware security module – ide o hardvérové zariadenie, ktoré slúži na krytografické operácie a uchovávanie privátnych kľúčov a tajomstiev. Používa sa pre to, že z neho nejde získať privátne kľúče softvérovo ani mechanicky, a chráni pred ich únikom aj v prípade chyby softvéru, aj v prípade odcudzenia zariadenia, ale aj voči takým veciam ako kompromitácia ľudského faktoru (ak sa použije správne).
PKCS#11 je platformovo neutrálny štandard pre rozhranie pre prácu s kľúčmi na kryptografických hardvérových zariadeniach ako sú HSM-ká a čipové/smart karty (napríklad Slovenské eID). Ide o API cca. 65 C-éčkových funkcii (exportovaných DLL-kou) a k tomu konštanty a štruktúry. Toto API umožňuje manažment kľúčov a iných objektov, podporuje podpisovanie, šifrovanie, hašovanie,… Často umožňuje použitie RSA, eliptických kriviek, AES šifry, SHA-2 hash funkcií,… Čipové karty podporujú zvyčajne len podpisovanie, zatiaľ čo HSM-ká implementujú omnoho väčšiu časť štandardu.
PKCS#11 API má svoje špecifiká, napríklad aplikácia sa musí voči nemu autentifikovať (to sa z bezpečnostných dôvodov robí často ručne). Ide o C API, takže namiesto rozumnej chyby sa vracia len všeobecný chybový kód (niečo ako kategória chyby napr. CKR_GENERAL_ERROR, CKR_ARGUMENTS_BAD, CKR_DEVICE_ERROR, CKR_PIN_INVALID,…) a konkrétnu chybu treba nájsť v logoch obslužného softvéru (dalo by sa povedať ovládača/driveru). Ďalším špecifikom je, že ID-čka nie sú unikátne a viac objektov môže mať zhodné CKA_ID. Objekty sa vyhľadávajú len na presnú zhodu atribútov.
Pri vývoji je dobré mať možnosť používať softvérovú náhradu HSM alebo čipovej karty. HSM-ko je pomerne drahá záležitosť, ktorá je zložitá na administráciu, nejde pichnúť do notebooku, čo sa v čase COVID-u a homeofficov ešte skomplikovalo. Zas čipové karty sú kvôli obmedzenému hardvéru pomerne pomalé a majú obmedzený počet zápisov. Obe tieto technológie sa ťažko používajú v unit testoch (technicky sú to integračné testy), hlavne na virtuálnych serveroch.
Niektoré pojmy z PKCS#11
- slot – reprezentácia čítačky kariet,
- token – reprezentácia čipovej karty,
- crypto objekt – dátová štruktúra na PKCS#11 zariadení, napr. privátny kľúč, verejný kľúč, certifikát, dátový objekt,
- atribút – vlastnosť/property crypto objektu, každý tym crypto objektu má sadu predpísaných vlastností ako
CKA_ID,CKA_LABEL,CKA_EC_POINT,… - privátny objekt – objekt, ktorý ma nastavený atribút
CKA_PRIVATEnatruea je s ním možné pracovať až po prihlásení do tokenu, - senzitívny atribút – atribút, ktorý nie je možné z objektu čítať (napr. hodnota privátneho kľúča),
- mechanizmus – reprezentuje operáciu/algoritmus na PKCS#11 zariadení, napríklad vytvorenie kľúčového páru, typ podpisu (RSA Pkcs1, RSA pss, ECDSA), typ šifrovania (AES, RSA oaep),…
Existujúce riešenie – SoftHSMv2
Softvérová implementácia HSM-ka s PKCS#11 rozhraním už jestvuje, ide o SohftHSMv2. Niekoľko rokov som ho používal, ale postupne mi pretiekol pohár trpezlivosti.
SohftHSMv2 je implementovaný ako natívna knižnica s pár obslužnými programami.
Na aké problémy som s ním narazil:
- malé množstvo podporovaných algoritmov (narazil som keď som potreboval použiť diffie hellman s KDF1, alebo niektoré varianty AES-u),
- podpora rôznych algoritmov na rôznych platformách (na CentOs 7 podporuje inú sadu eliptických kriviek ako na Debian 11),
- nefunkčné logovanie najmenej od roku 2017 (issue + kody) – na Windowse od začiatku nefunguje logovanie do EventLogu, na linuxových systémoch zas musí logovanie povoliť integrujúca aplikácia do syslogu (logovanie je naozaj dôležité pri vývoji), a tieto problémy neboli doposiaľ opravené,
- od roku 2020 je nefunkčné CI pre Windows,
- tým, že ide len o knižnicu, tak si krypto objekty (kľúče) ukladá na súborový systém, to spôsobuje problémy, že keď chcem službe na testovacom prostredí pridať nové kľúče, tak ich nevidí, lebo je spustená pod iným používateľom a treba ručne „hekovať“ súbory kľúčov na disku,
- ak vaša aplikácia používa inú verziu OpenSSL knižnice ako SoftHSM, pravdepodobne vám pri prvom volaní aplikácia padne,
- problémové použitie pri unit/integračnom testovaní,
- netriviálne použitie cez Docker,
- komplikované použitie cez CMD nástroje (ja rád klikám).




Požiadavky na BouncyHsm
BouncyHsm som sa rozhodol robiť pre to, aby som si vyriešil vyššie spomínané problémy a uľahčil si prácu. Taktiež som chcel dosiahnuť, aby výsledné riešenie bolo „developer frendly“ a ľahko sa nasadzovalo a používalo.
Ak som chcel vyriešiť vyššie spomínané problémy, tak od začiatku som vedel, že na kryptografické operácie použijem BouncyCastle, budem sa vyhýbať natívnym závislostiam, a že riešenie bude rozdelené na natívnu PKCS#11 knižnicu a .NET aplikáciu.
Z tohto všetkého vychádzajú nasledovné požiadavky:
- čo najväčšie množstvo kryptografických funkcií zo štandardu PKCS#11 v2.40,
- podpora Windowsu, Windows Serveru, niektorých linuxov,
- podpora x86 a x64 architektúry,
- rovnaké chovanie na rôznych platformách
- podpora viac-aplikačného súbežného prístupu cez PKCS#11 knižnicu,
- jednoduchá inštalácia (rozbalím archív a môžem používať),
- natívna PKCS#11 knižnica bez závislostí na iných knižniciach (rieši to depenceny hell na linixe),
- možnosť používať podpisový PIN (ako simuláciu čipových kariet),
- bohaté logovanie na strane natívnej knižnice aj na strane samotnej aplikácie,
- možnosť obísť PKCS#11 štandard:
- pozrieť sa na privátne kryto objekty,
- pozrieť sa na senzitívne atribúty,
- možnosť jednoducho importovať P12/PFX, privátny kľúč tak ako keby vznikol v HSM-ku,
- kvôli použiteľnosti v testoch mať možnosť ovládať BouncyHsm programovo,
- mať k tomu administračné GUI, kde sa bude dať všetko pohodlne pozrieť a naklikať,
- zrozumiteľnosť technológií pre iných vývojárov.
Chcel by som ešte zdôrazniť, že ide o simulátor a rovnako, ako v SoftHSMv2 neriešim bezpečnosť ukladania kľúčov a prenos dát.
Výber technológií, architektúry, protokolu
S experimentálnou fázou som začal v decembri 2022, keďže nízkoúrovňový driver komunikujúci s .NET aplikáciou bolo pre mňa niečo nové, tak namiesto implementácie som strávil niekoľko týždňov výberom technológií a navrhovaním protokolu. Každej technológii som dal čas a skúsil si s ňou implementáciu jednej funkcie, aby som nebol neskôr prekvapený.
Od začiatku som vedel, že použijem BouncyCastle, lebo implementuje takmer každý kryptografický algoritmus, na ktorý si človek spomenie, a všetko pomocou manažovaného kódu, takže nemá natívne závislosti. Taktiež som vedel, že administračné GUI musí byť webové, aby sa dalo ľahko použiť na serveroch. Navyše som vedel, že natívna PKCS#11 knižnica nemusí mať rovnakú procesorovú architektúru ako obslužná aplikácia.
Na nasledujúcom obrázku sú znázornené jednotlivé predpokladané komponenty systému.
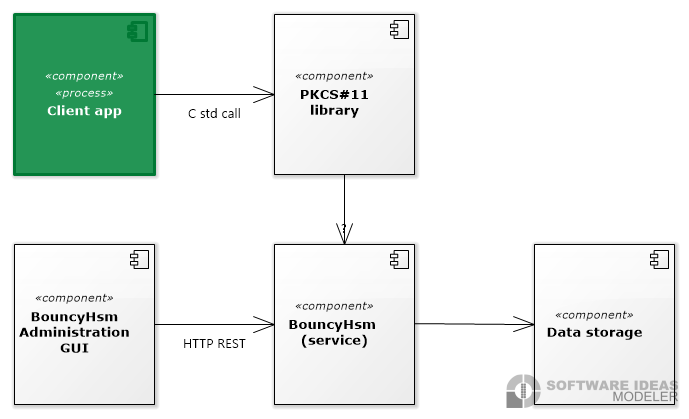
Výber technológií pre natívnu knižnicu
Keďže PKCS#11 knižnica musí byť natívna, tak možné technológie ovplyvnili výber a návrh protokolu, lebo ide o najviac obmedzujúci faktor. No súčasne som chcel, aby sa do vývoja mohli zapojiť aj iní programátori, tak som spočiatku cielil na REST (skôr REST-like API s JSON-om), gRPC alebo websokety.
Ako implementačné jazyky som zvažoval C#, Rust a C, lebo dokážu vytvoriť natívnu DLL-ku.
Výber technológie
C# - od .NET 7 umožňuje pomocou AOT kompilácie vytvoriť natívne aplikácie a DLL-ky. Ako experiment som si spravil DLL-ku, ktorá načítala dáta z OpenWeatherMap a vrátila ich cez parametre. No tu som narazil na problém, že v tejto verzii nevie exportovať funkcie s pointermi na štruktúru (čo sa samozrejme dá obísť pretypovaním), no aj binárka mala niekoľko MB (v .NET 8 boli oba tieto problémy vyriešené) a na linuxe som sa bál závislostí (OpenSSL).
Rust – skúsil som podobnú implementáciu a narazil na iné problémy: hrozne veľa unsafe kódu, neustále konverzie rôznych typov stringov, konverzia číselných typov, ich deklarácie boli problematické (kvôli rôzne veľkým numerickým typom na rôznych platformách a architektúrach) a k tomu rovnaké problémy ako v predchádzajúcom príklade: binárka pre Windows mala 12MB a tiež nejasné závislosti v knižniciach, plus do budúcna mi nik negarantuje, že sa nezmenia.
C – späť ku základom. Tu si viem jasne definovať závislosti, kód nebude horší ako v Ruste a pre PKCS#11 sú už hlavičkové súbory definované. Tak nakoniec som zvolil implementáciu v C.
Následne som začal skúmať možnosti, ktoré mám pri C implementácii, hlavne transportnú vrstvu protokolu.
Transportná vrstva
Native messaging – fungovalo by to tak, že DLL-ka by si spustila aplikáciu, z ktorou by komunikovala cez STDIN a STDOUT, je to jednoduché a bezpečné riešenie, ktoré navyše izoluje aplikácie a komunikáciu, no prináša komplikácie s tým, že proces, ktorý načíta danú DLL-ku musí mať práva spúšťať iné programy a veľa práce si neušetrím, lebo aj tak bude treba vmyslieť obdobný komunikačný protokol ako v ostatných prípadoch.
HTTP/S – na Windowse záležitosť na pár riadkov s WinHttp, a to vrátane HTTPS a trustu, na linuxe boj s cURL a OpenSSL.
WebSocket – podobná situácia, na Windowse súčasť WinAPI, na linuxe treťostranné knižnice s úplne iným programátorským modelom a prístupom. Navyše pri websocketoch by som musel riešiť timeouty (aplikácie môžu bežať mesiace), obnovovanie spojenia a multithreading, čo by pridalo ďalšiu vrstvu zložitosti.
TCP – nakoniec som skončil s holým TCP. RPC cez TCP spôsobom, že pre každý request a response použijem samostatné spojenie má výhodu v jednoduchosti, nemusím riešiť lockovanie a multithreading, na Windowse a linuxe majú veľmi podobné API (winsock, posix socket) a hlavne k tomu netreba žiadnu externú knižnicu.
Protokol
Súčasne s výberom transportnej vrstvy som vyberal aj protokol, respektíve, ako budem serializovať dátové štruktúry pri volaní a odpovediach zo serveru. Zvažoval som niekoľko formátov, tu už bolo dôležité, aby si z daným formátom poradil aj .NET (C#).
JSON – JSON som zvažoval ako prvý, hlavne kvôli jeho populárnosti a tomu, že preň je plno knižníc pre jazyk C. Spravil som z knižnicami niekoľko úspešných experimentov, mali prijateľné API. Síce som musel riešiť prevod do base64 a späť, ale to je vyriešený problém. No potom som narazil pri číslach v JSON-e. Číslo v JSON-e, je také morské prasiatko – ani celočíselný typ ani double. Dané knižnice často implementovali len jedno z toho. Štandardný JSON, nedokáže preniesť ulong (64-bitový int bez znamienka), čo je pri PKCS#11 stopka. A kódovať čísla ako stringy sa mi nechcelo.
ProtoBuffer – dúfal som, že vďaka proto súborom budem môcť vygenerovať serializačný a deserializačný kód pre C aj C#. No pre C som našiel len jednu aktuálnu knižnicu a aj tá bola platená.
MessagePack – MessagePack je otvorený binárny sterilizačný formát, ktorý kombinuje kompaktnosť ProtoBufferu a samopopisnosť JSON-u. To znamená, že je veľmi malý, relatívne jednoduchý a nie je potrebné mať k nemu schému aby sa dal interpretovať. Navyše binárne dáta nie je potrebné špeciálne enkódvať a zvláda aj ulongy, „DateTime“ či iné dátové typy (vďaka rozšíriteľnosti).
Nakoniec som zvolil MessagePack, pretože som naň našiel one file knižnicu pre C (celá knižnica je v dvoch súboroch – C-éčkový kód a hlavičkový súbor). Oproti ostatným formátom, ale nemá štandardnú schému, alebo OpenAPI pomocou, ktorého by som mohol vygenerovať server a klienta. To som ale vyriešil vlastným generátorom. Ten zoberie definíciu RPC (volania a dátové štruktúry popísané v YAML súbore). Z nich vygeneruje pre každú dátovú štruktúru: C štruktúru, metódy na serializáciu, deserializáciu a dealokáciu, pre C# vygeneruje C# triedu s príslušnými anotáciami. Pre RPC volanie je zas vygenerovaná metóda, ktorá dostane vstupnú štruktúru, výstupnú štruktúru a TCP spojenie, pre C# sa vygeneruje rozhranie pre handler (podobný ako používa MediatR), parciálna trieda, ktorú je nutné implementovať na to aby sa kód skompiloval a globálny handler, ktorý deserializuje request podľa jeho hlavičky a zavolá konkrétny handler.
Samotný protokol sa skladá z troch častí: hlavičky správy, hlavičky requestu a tela requestu.
Hlavička správy - je dlhá 8 bajtov. Prvý bajt je identifikátor protokolu 0xBC, druhý je číslo verzie protokolu (v tomto prípade 0x00), nasledujúce dva bajty sú veľkosť hlavičky requestu kódované v BE (big endian) a posledné štyri sú veľkosť tela requestu kódované v BE.
Hlavička requestu – obsahuje messagepack pole, kde prvá hodnota je meno operácie, druhá hodnota je tag, ktorý sa môže použiť na filtrovanie v logoch.
Telo requestu – je messagepack objekt, ktorý je definovaný pre danú operáciu.
Odpoveď má rovnakú štruktúru, ale hlavička response je len pole z jednou rezervovanou hodnotou.
Pre možnú odlišnú bitovosť nemôžem posielať dáta PKCS#11 funkcií do dotnetovej aplikácie stranu priamo. Kvôli práci z nízkoúrovňovou reprezentáciou dát v PKCS#11 knižnici som priamo v nej nepoznal kontext a napríklad pri PKCS#11 atribútoch neviem v tejto knižnici určiť ich dátový typ, takže ich kódujem do všetkých možných (ulong, binárne dáta, string, dátum) a až dotnetová strana sa rozhodne, ktorú reprezentáciu použije.
Logovanie
Cez premennú prostredia je možné nastaviť úroveň a ciel logovania. Volil som spôsoby logovania, ktoré zvládne každá aplikácia. Ako defaultné som zvolil zápis chybových logov na STDERR.
Medzi ďalšie možnosti patrí vypnuté logovanie, STDOUT, syslog pre linux, WinDebug pre Windows (dá sa sledovať pomocou nástroja WinDbg zo SysInternals).
Výber technológie serveru
Pri výbere technológie serveru to bolo viac menej jasné – ASP.NET Core WebApi, ktorá bude počúvať na TCP porte pre pripojenie natívnej knižnice, vystaví RESTové API pre manažment a administračné GUI.
Túto časť som sa rozhodol robiť v duchu clean architecture a teda aplikačná logika vôbec netuší o úložisku dát, ani to, že je volaná cez REST-ové API a TCP RPC. V ponímaní tejto architektúry tu máme entity – v mojom prípade crypto objekty (s celý stromom dedenia ako v štandarde), prípady použitia mám dvoch druhov – PKCS11 handlery (obsluhujú volania cez PKCS#11 knižnicu) a UseCases (obsluhujú volania cez REST-ové API). UseCases ale nie sú riešené na štýl vertical slice architecture (MediatR) ale použil som fasády.
Na nasledujúcom obrázku je UML diagram implementovaných crypto objektov.
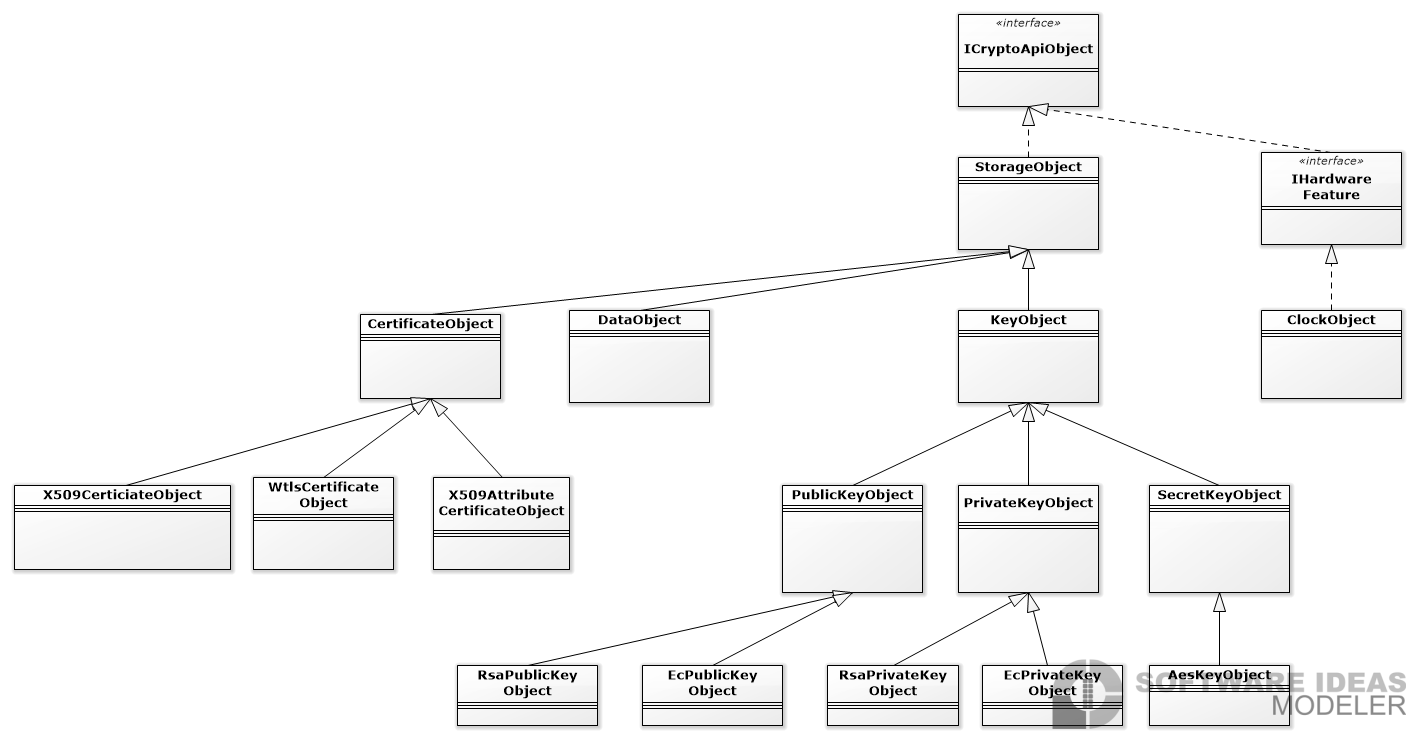
S crypto objektmi dosť úspešne pracujem pomocou visitoru, ktorým viem objektom pridať funkcionalitu bez dedenia (napríklad skonštruovať používateľsky príjemné pomenovanie objektu, alebo export objektu do PEM enkódingu).
Na projekte som tiež použil knižnice NSwag, MessagePack-CSharp, BouncyCastle.Cryptography, Dunet, Pkcs11Interop (autorovi tejto knižnice patrí špeciálna vďaka).
Výber technológie úložiska
Pri výbere úložiska som postupoval tak, že najskôr som si ho implementoval in-memory a zistil, čo vlastne potrebujem – niekoľko indexov, takmer žiadne relácie. Pôvodne som chcel použiť relačnú databázu (MsSQL a Sqlite). Použiť Sqlite by síce znamenalo, použiť niečo, čo každý pozná, ale nechcel som pridávať natívne závislosti, tak som použil LiteDb (zvažoval som aj ZoneTree) a pri prevádzke som zatiaľ nenarazil na problém (pri testoch som skúšal do nej naliať niekoľko GB dát).
LiteDB je embeded dokumentová databáza napísaná v manažovanom C# kóde, kde API vychádza z MongoDb. Podporuje indexy, LINQ dopytovanie, GridFs API a transakcie. Viac som nepotreboval. Výhoda je, že databázu tvorí jediný súbor, takže ide ľahko prenášať medzi inštanciami. Dobrá vec je aj to, že LiteDB má priamo od tvorcov administračný nástroj.
Výber technológie administračného GUI
Ako som už spomínal, kvôli tomu, aby bolo administračné GUI dostupné aj pri práci na serveri som sa ho rozhodol spraviť webové.
Aby bola aplikácia postavená na rozšírených technológiách, tak som chcel využiť Vue3, s ktorým mám dobré skúposti a ľahko sa s ním pracuje.
No počas prípravnej fázy som v práci dostal úlohu v Angularovom projekte zmeniť dva stringy. Ale mal som novší nodejs ako bol na projekte, tak som sa pustil do upgradu projektu. Návod z oficiálnej stránky nefungoval, lebo som mal príliš nové nodejs. Takže bolo potrebné všetko spraviť ručne, zdvihnúť Angular, všetky závislosti zo svojím dependecny hell, typescript,… A tak sa z úlohy, čo mala trvať päť minút stalo dvojtýždňové trápenie. Preto som si povedal „████ node“ a rozhodol sa, že si nebudem robiť zle, administračné GUI proste spravím v Blazor Webassembly.
Frondend je nakoniec postavený na Blazor WebAssembly, REST-ovom API, SignalR a Bootstrape.
Výber licencie
Licenciu som vyberal tak, že som chcel aby si hocikto mohol projekt zobrať a upraviť si ho podľa potreby a nemusel zverejniť zmeny (niektorí výrobcovia HSM-iek poskytujú dokumentáciu ku svojej špecifickej funkcionalite pod NDA-čkou), no súčasne nechcem aby si na tomto projekte niekto postavil biznis a ja z toho nemal nič. Takže tým odpadli úplne voľné licencie ako MIT a súčasne aj nákazlivé ako GPL3. Zostali v podstate dve licencie BSD 3-Clause a Apache license 2.0. Zvolil som BSD 3-Clause License, lebo sa mi nechcelo uvádzať licenciu v každom zdrojovom súbore projektu.
Možná budúca práca
Do budúcna uvažujem aj s ďalšou funkcionalitou, ak sa ukáže, že bude potrebná.
Napríklad:
- nuget pre integračné testovanie aplikácií (pre MS Test v2, xUnit),
- proxy, ktorá prevedie TCP RPC na HTTPS volania na server,
- podpora zadávania PIN-u cez „protected path“, to znamená, že BouncyHsm zobrazí okno, do ktorého sa zadá PIN (podobne ako Slovenské eID),
- možnosť vytiahnuť token zo slotu,
- podpora novšieho štandardu PKCS#11, keď bude podporovaný reálnym hardvérom (v súčasnosti sa objavujú len niektoré mechanizmy okolo ED25519),
- možnosť pridať profily so zakázanými/povolenými mechanizmami a určiť maximálnu veľkosť úložiska, pre simuláciu konkrétnych typov HSM/kariet,
- implementácia iných úložísk ako LiteDb napríklad nejakej relačnej databázy.
Čo som sa naučil
Tento projekt ma naučil, že treba byť opatrný pri výbere knižníc a protokolu.
Tiež som sa naučil, že špecifikácie nemusia byť úplne jasné a ku niektorým častiam nenájde príklad použitia ani google, ani github a nepomože ani umelá inteligencia. No prenikol som do tejto špecifikácie hlboko.
Aj vďaka tomuto projektu som sa stal kontribútorom BouncyCastle, tým, že som doň poslal opravy niektorých štruktúr, chýbajúcich drobností, na ktoré som narazil a tiež drobné zlepšenia performace. Nebolo to za deň, ale bolo potrebné sa do toho dostať a tiež codebase tohto projektu nie je malá ani jednoduchá (keď človek niečo hľadá tak dekompilátor je dobrý kamarát). Odvtedy sledujem issues aj pull requesty BouncyCastle.
Takisto som sa dostal aj do WinApi a vývoja pre linux. Na škole mi tvrdili, že na linuxe sa programuje ľahšie, bola to lož. Zatiaľ, čo Windows ma takmer na všetko API, tak na linuxe tu treba buď čítať z textového súboru (ktorý môže byť inde a v inom formáte v závislosti od distribúcie a verzie) alebo použiť nejakú treťostrannú knižnicu. Linuxu, repektíve glibc tiež chýbajú štandardné bezpečné C-éčkové funkcie, ktoré naopak MSVC vyžaduje (strcpy vs. strcpy_s).
Naučil som sa používať make.
Vyskúšal som si clean architektúru na projekte, kde pomohla s tým niektoré architektonické rozhodnutia odložiť na neskôr. Táto architektúra pomohla pre to, že doména šla namapovať priamočiaro na entity, doménovú logiku a prípady použitia (termín z Clean architektúry).
Záver
Po niekoľkých mesiacoch práce po večeroch sa mi podarilo vytvoriť simulátor hardvérového zariadenia (HSM), ktorá mi pomáha v práci a šetrí nervy. Naučil som sa nové veci a stal som sa kontribútorom významného otvoreného projektu.
Z výsledkom som spokojný, klikať si v GUI je oveľa pohodlnejšie ako riešiť CLI komandy alebo obskúrne PKCS#11 nástroje a hlavne to loguje. Síce GUI vyzerá ako od backend programátora ale to stačí.
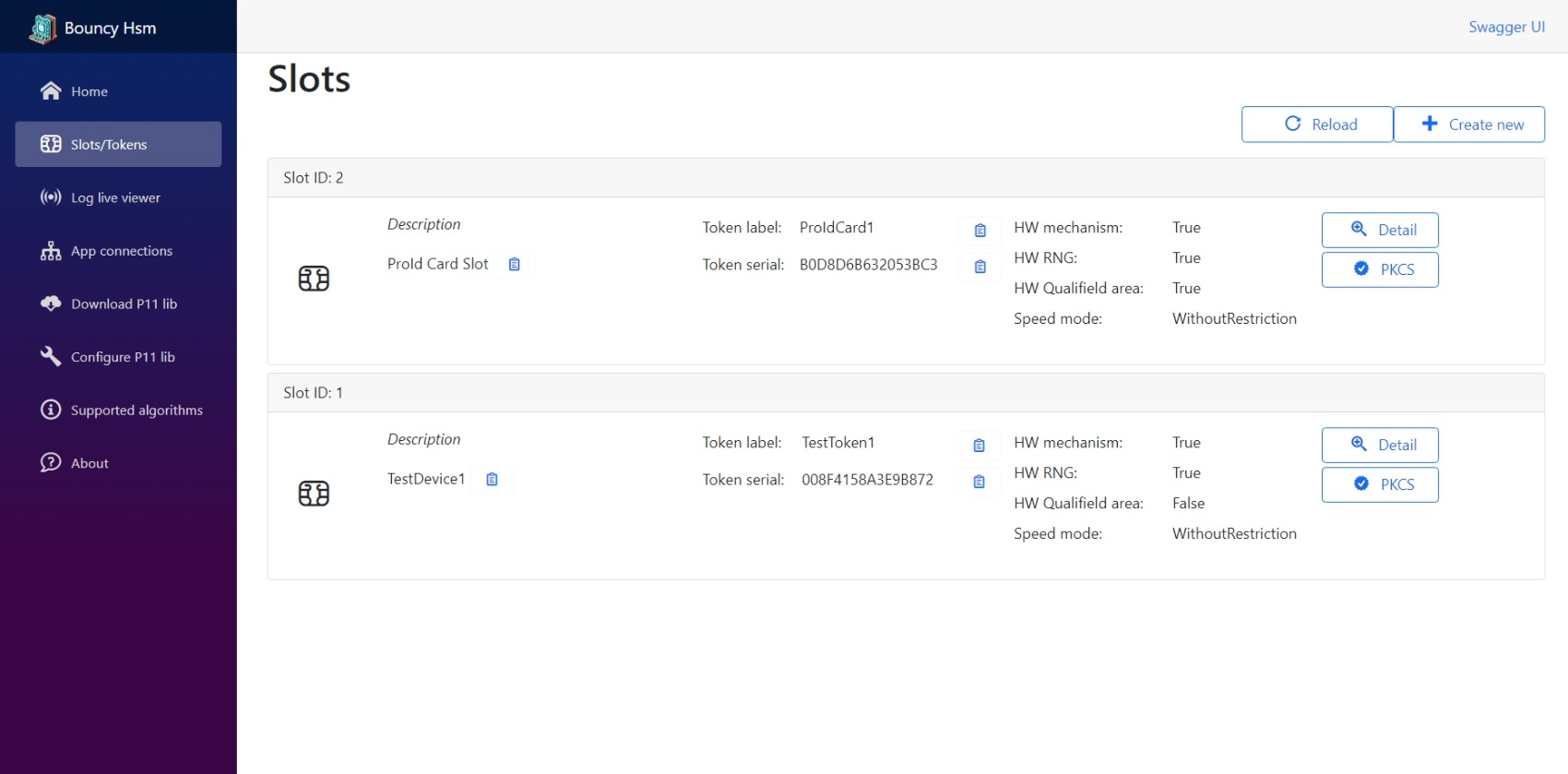
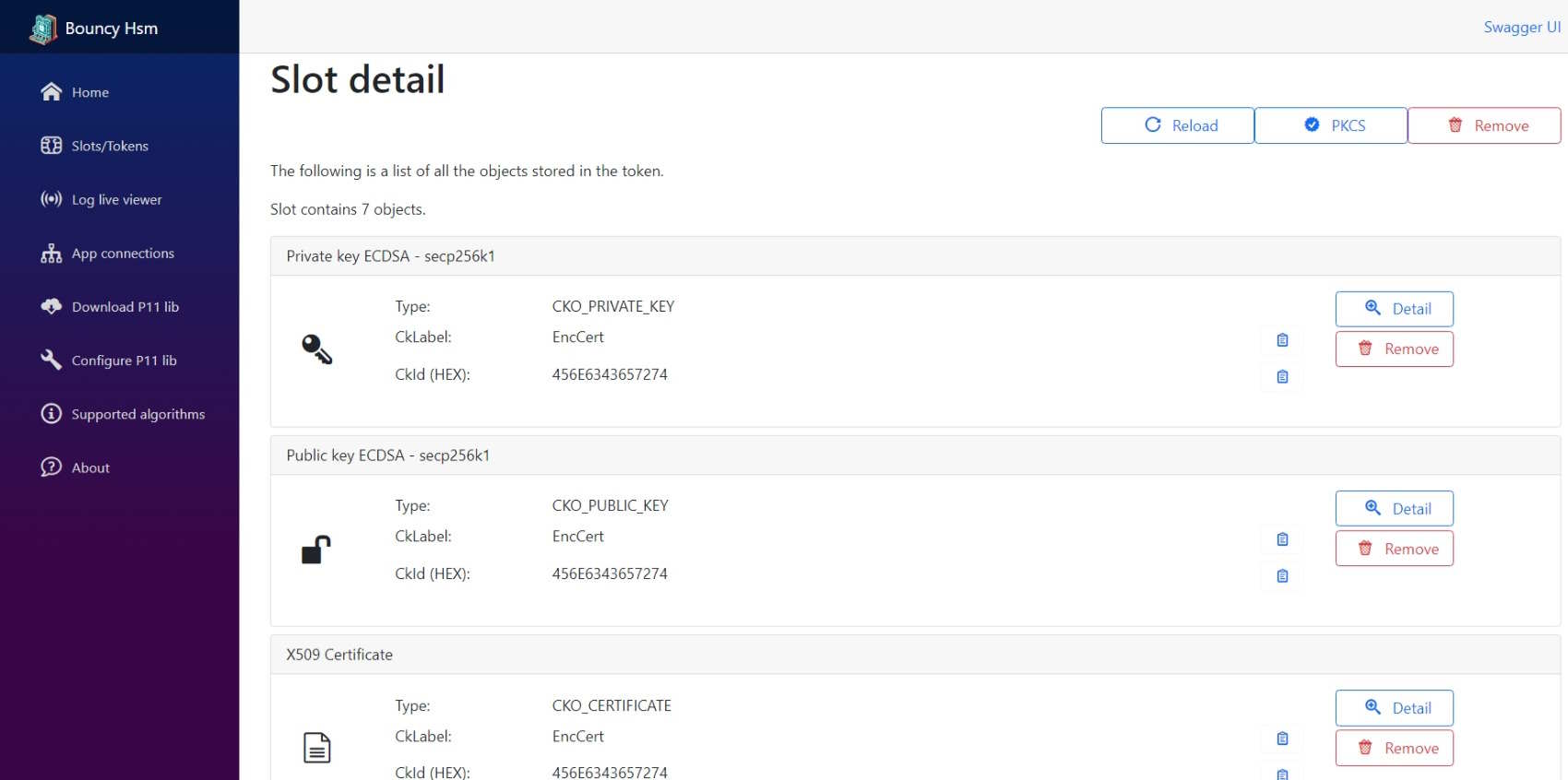
Vďaka čistému C-éčku je možné PKCS#11 knižnicu skompilovať na všetkom a celý projekt sa mi dokonca podarilo rozbehať na Raspberry PI Zero 2.
No sú aj veci, ktoré sa mi nepodarili. Ku časti mechanizmov zo štandardu nejestvuje zariadenie, ktoré ich implementuje, ani špecifickejšie zdroje na internete alebo príklad kódu, ktorým by som si overil správnosť mojej implementácie. Tak som implementoval tie časti, ktoré sa dali, a ktoré sa používajú. Pôvodne som chcel ku BouncyHsm aj systém pluginov na rozširovanie funkcionality, ale to sa nedá riešiť univerzálne, lebo vendor špecifické veci často vyžadujú zásah aj do kódu natívnej PKCS#11 knižnice.