Experiment - Content filter
Mojím pôvodným zámerom bolo zistiť, či ide strojovo rozlíšiť hodnoverný medicínsky článok od článku propagujúce pochybné liečiteľstvo a medicínsky bulvár, či konšpiračné články a vytvoriť tak niečo ako anti-spamový filter pre tieto články. Podarilo sa mi zhromaždiť 101 unikátnych pochybných článkov a po veľkej námahe 68 serióznych článkov.
Technická realizácia
Pri realizácii som nevymýšľal nič nové, inšpiroval som sa prácou, ktorá identifikuje sentiment (3). Voľba padala na Tf-Idf váhovanie(2), Hunspell s českými slovníkmi na určenie koreňa slov, odstraňovanie stop-slov (slová, ktoré samé o sebe nemajú význam) a SVM (1) (support vecror machine).
Použité knižnice
- Accord.NET
- NHunspell
SVM
SVM je moderná forma strojového učenia (umelej inteligencie), ide o binárny štatistický klasifikátor, medzi hlavné výhody patrí schopnosť pracovať s vysoko dimenzionálnym priestorom. Úspešne sa používa napríklad v anti-spamových filtroch, rozpoznávaní rukou písaných číslic, kvetiniek (4), v určovaní malígnosti alebo benignosti nádoru prsníka (5), (6) a predikcie spájania aminokyselín (7).
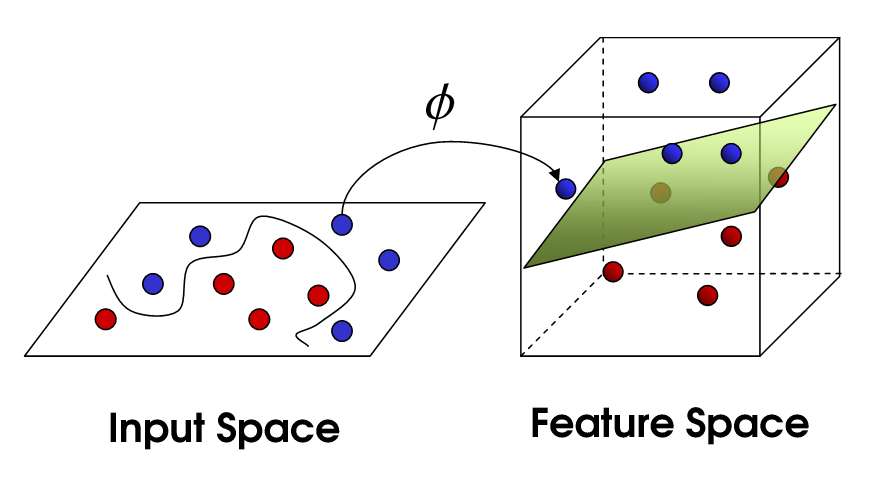
Jedným zo základných princípov SVM je prevedenie pôvodného priestoru do priestoru s oveľa vyššou dimenziou, kde sa už dajú rozdeliť triedy pomocou deliacej nadroviny. Prevod vstupných hodnôt do vyšších dimenzií zabezpečuje kernel funkcia.
"SVM sa pri učení snaží nájsť optimálnu deliacu nadrovinu, ktorá maximalizuje hranice medzi triedami. Ak ju nedokáže nájsť, prevedie pôvodný problém v n-rozmernom priestore na omnoho vyšší, v ktorom je možné lineárne separovať triedy nadrovinou. Pri mapovaní do priestoru s dostatočne vysokým počtom dimenzií je vždy možné nájsť nadrovinu, ktorá oddeľuje triedy problému. Lineárna nadrovina sa hľadá pomocou metódy kvadratického programovania." (8)
SVM bolo natrénované s Gausovým kernelom, parametrom clomplexity = 4.0, vektor dokumentu mal veľkosť 20 603 (to znamená, že dokumenty obsahovali okolo 20 603 unikátnych termov) a na vyhodnotenie bola použitá krížová validácia.
Výsledky
| Hodnoverný článok | Pochybný článok | |
|---|---|---|
| Precision | 86% | 93% |
| Recall | 89% | 91% |
Záver
Predpokladám, že pri kvalitnejšom predspracovaní termov a hlavne trénovanie pomocou datasetu, ktorý obsahujú rovnaký počet kladných aj záporných vzoriek, by sa presnosť pohybovala aspoň na 95%.
Rovnakým princípom je možné filtrovať aj iné druhy článkov, stačí SVM vhodne natrénovať, pretože je schopné dostatočného zovšeobecnenia problému.
Zdroje
- http://is.muni.cz/el/1433/podzim2006/PA034/09_SVM.pdf
- http://people.tuke.sk/jan.paralic/knihy/DolovanieZnalostizTextov.pdf
- http://ics.upjs.sk/~krajci/skola/ine/SVK/pdf/Kuper.pdf
- https://code.google.com/p/accord/wiki/SampleApplications (aplikácia na stiahnutie)
- http://www.doaj.org/doaj?func=fulltext&aId=1463627
- http://axon.cs.byu.edu/Dan/778/papers/Feature%20Selection/guyon*.pdf
- http://www.fi.muni.cz/~lexa/hroza_hudik.pdf
- Gajdos J., Identifikácia parafrázovania v textových dokumentoch